
当地时间4月16日,OpenAI宣布推出GPT-5.3-Codex-Spark——一款专门针对编程场景的快速推理模型。同一天,OpenAI还发布了面向药物研发领域的GPT-Rosalind、面向网络安全的GPT-5.4-Cyber,连续三款模型密集发布。一周前,OpenAI刚刚宣布GPT-5.2推理速度提升40%,整个行业为之震动。
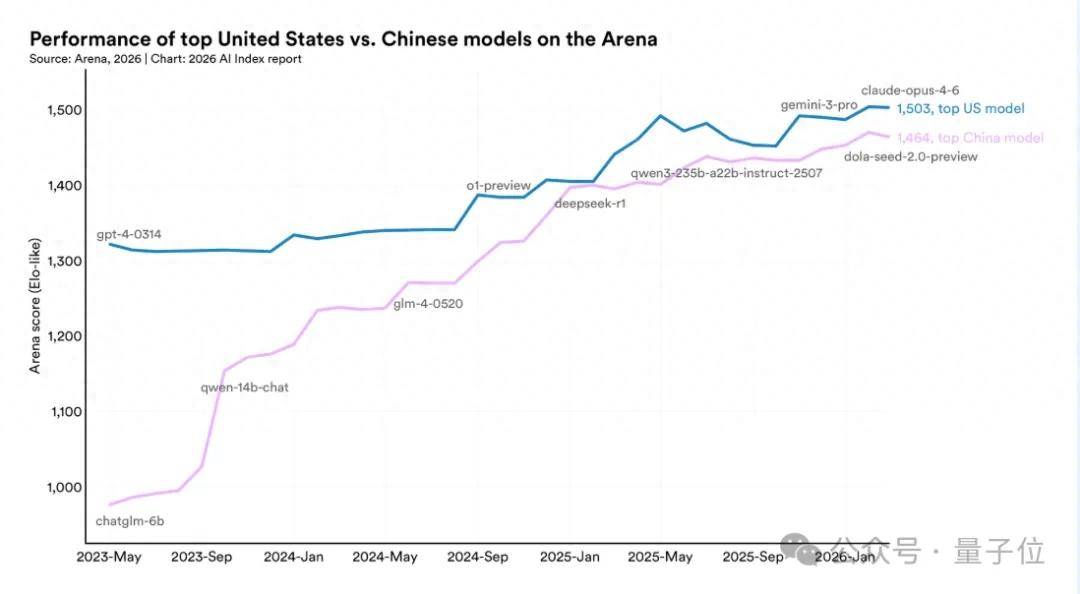
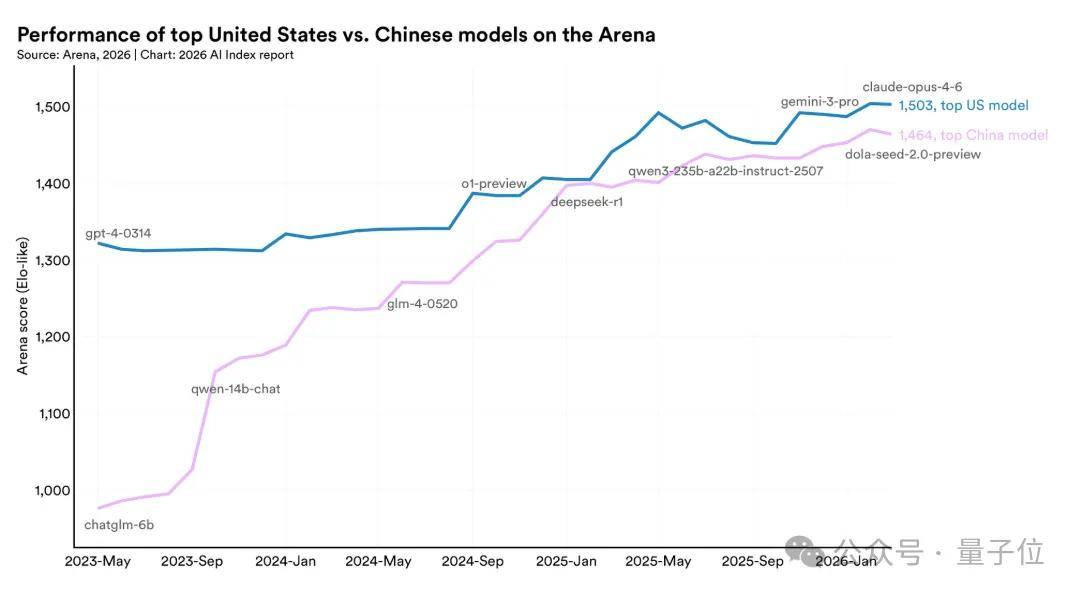
然而,中国AI的回应同样令市场意外。斯坦福最新AI指数报告显示,中美大模型性能差距已从2023年的300多分缩窄至如今的2.7%,几乎抹平。这场AI军备竞赛,正在迎来最激烈的拐点。
OpenAI的焦虑:连发三款,防守意图明显
OpenAI正在经历一场罕见的战略急转弯。
就在GPT-Rosalind和GPT-5.4-Cyber发布的前一天,OpenAI刚刚对外展示了GPT-5.2模型——在参数权重完全不变的情况下,推理速度整体提升40%。这一数字并非来自模型架构的根本改变,而是来自推理栈的工程化优化,意味着所有API客户无需任何代码调整即可直接受益。
连续三款新品密集发布背后,是OpenAI市场份额正在被蚕食的现实。根据斯坦福AI Index报告的数据,截至2025年8月,OpenAI仍占据全球AI模型访问量的93%。但DeepSeek R1发布后短短两个月,中国模型的全球市场份额从3%急升至13%,增长幅度高达460%,覆盖30多个国家。
更令OpenAI不安的,是开源社区的崛起。阿里最新发布的Qwen3.5-27B,在综合智力评测中与GPT-5打成平手——一个27B参数的小模型,得分与千亿级参数的GPT-5完全对等。
中国AI的底牌:开源破局,价格屠夫
如果把OpenAI比作AI界的苹果,那中国大模型正在扮演安卓的角色——用开源和低价彻底颠覆游戏规则。
DeepSeek V4将于4月下旬发布,万亿参数、百万级上下文窗口、原生多模态,并确定以Apache 2.0协议完全开源。这一消息被业内视为国产AI向全球第一梯队发起总攻的终极武器。
价格是中国大模型最锋利的矛。GPT-5.4 Pro处理100万输出Token的成本约为69元人民币,而DeepSeek V3.5处理同等输出仅需4元——差距高达17倍。更让美国公司感到压力的是,中国模型在推理速度上也实现了反超:国内模型推理速度普遍在6500-8500 Token/秒,延迟低于50毫秒,而GPT-5系列约为4000-6000 Token/秒。
国内大模型第一梯队包括通义千问3.5、豆包5.0、DeepSeek-V3.2、文心一言5.0,综合能力逼近GPT-5,差距约3-7个月。更值得注意的是,在中文理解、古文、方言、政务文书等本土化场景上,中国模型已全面领先,准确率超出海外模型30%以上。
2.7%差距背后的真相:智力追平,知识仍有鸿沟
斯坦福报告显示,中美AI差距已缩窄至2.7%,这是一个令人振奋的数据。但专业人士提醒,智力的追平并不等同于能力的等效。
Artificial Analysis智力指数v4.0显示,Qwen3.5-27B在中等推理强度评测中拿到42分,与GPT-5打成平手,Gemma 4-31B拿到39分,对齐GPT-5低推理强度。但评测机构同时指出:小参数模型在事实知识存储上存在物理瓶颈——27B和31B的参数规模,装不下GPT-5量级的世界知识,靠多想几步是补不回来的。
GPT-5完全体(代号Gobi)预计将引入专门的推理模块,在生成Token前进行多路径并行模拟,用架构创新解决知识容量问题。这是小参数模型单纯靠推理优化无法跨越的护城河。
换句话说,中国AI在会用上已经迎头赶上,但在记住所有知识这一维度上,差距依然存在。这2.7%,或许正是这道鸿沟的宽度。
格局已变:AI进入多极时代
2023年,ChatGPT-4以1320分领跑全球时,中国最强模型ChatGLM-6B的得分还停留在900分区间,差距超过300分。三年后的今天,全球AI格局已从一超多强演变为中美双雄。
Claude Opus 4.6以1503分暂时领先,但中国dola-seed-2已在身后紧追不舍,双方差距微乎其微。AI军备竞赛正式进入贴身肉搏阶段。
对于普通用户而言,这场竞争带来的是实打实的红利:更强、更快、更便宜的AI工具正在加速普及。GPT-5.2提速40%后,API调用成本实质下降;DeepSeek V4开源后,企业和个人开发者将获得免费的高性能大模型。
但更深层的改变在于:AI时代的话语权正在从美国单极向多极转移。谁能最终定义AI的未来,现在远没有定论。
你觉得,中美AI这场竞赛,最终会走向合作还是持续对抗?你更看好开源路线还是闭源路线?欢迎在评论区说说你的看法,觉得有收获就点个赞/在看/收藏吧。
